Client
An early stage startup was pioneering the use of machine learning to read and make sense of unstructured data in real estate documents.
The challenge
People have a very high bar of expectations for machine learning— they expect near infallibility. Many data extraction processes are currently being done by hand, which yields incredibly accurate data (but at a high cost).
While the technology we were using made great gains there were still two challenges. What is the trust threshold wherein a user feels confident to fully trust a model? And secondly, when the model is not correct, how can our model learn from how the user corrects it?
My Role
Researcher, designer and tester. I collaborated with the other designer on the team who founded the company. While I picked up a lot of the research actions when I joined the team, there was a rich foundation to begin from. We worked together to design the flow we tested in this study.
Approach
- Interaction design and prototyping
- Lean usability testing
- Interviews and remote contextual studies
The story of trusting the machine
When introducing machine learning in a disruptive fashion, there’s often a trust gap that a new product needs to overcome. Through interviews and contextual studies we learned that users had a very high level of confidence in their data. If they paid someone to excerpt information from a document they expected perfection.
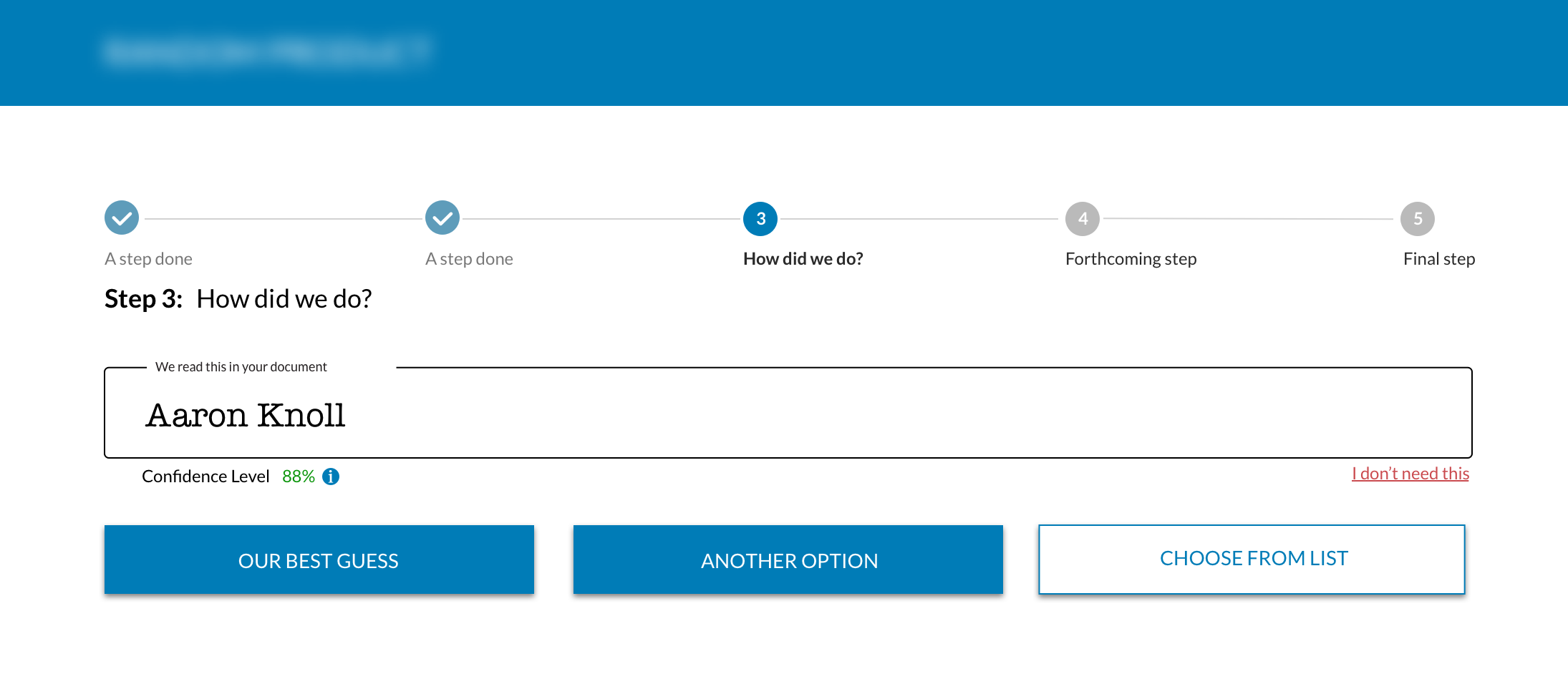
Initial concepts closely emulated existing mental models for processing large amounts of information. “Excel-like” and tabular representations were among the first concepts we started with; however, technical limitations precluded this. We needed another way for users to engage with the data.
We interviewed and observed the work of the people who were hired to do the manual data extraction. During interviews they often said “this is easy, it only takes me a few minutes.” However during observations, we saw something a bit different. It took users 25-30 minutes to process a document.
Whatever the reason we knew our perceptual baseline: “easy” and “quick.” We also knew our actual baseline. Whatever we designed needed to be quicker than the actual thirty minutes they were spending.
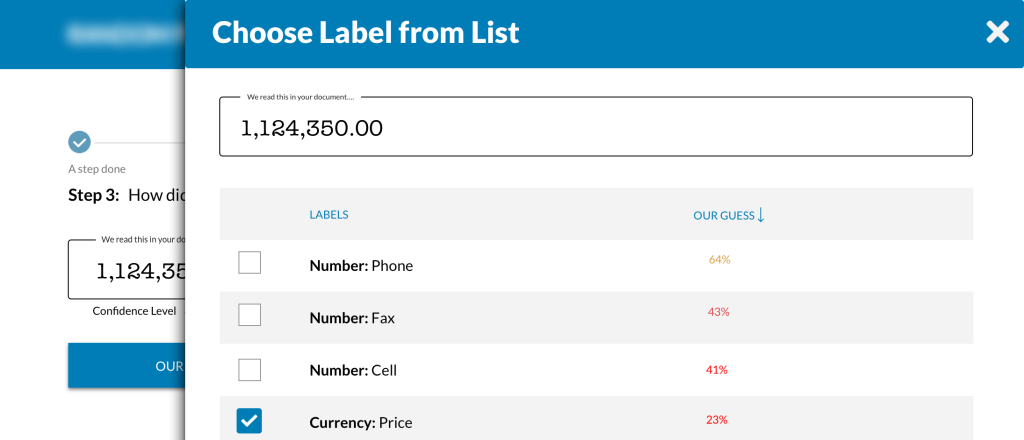
We tested several iterations of the product to balance the need for speed and the technical requirement of gathering human identification of data points our models missed. We tested with both non-professionals and commercial real estate professionals.
Among the challenges of doing this work during the pandemic of ’20-’21 was that we were unable to be co-located with the users we were testing with. We had to find another way to conduct an eye-tracking study. Leveraging an AI tool, we were able to do a heuristic analysis of where our designs were drawing attention.
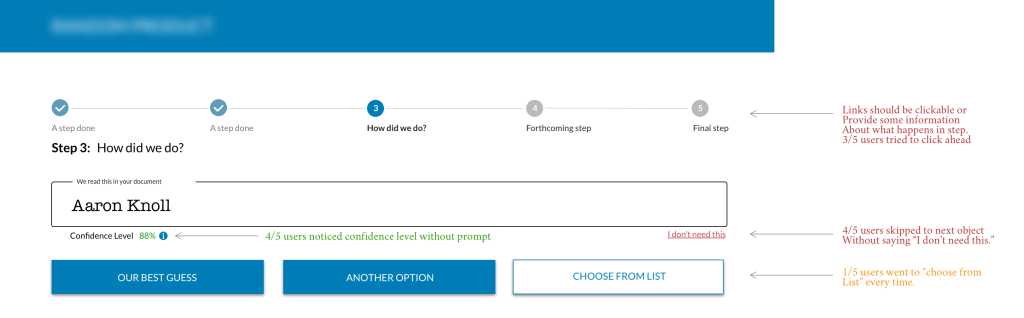
Through iterative testing we began to see returns on our testing. Users were more quickly able to correct data points; they were correcting data points. In our final round of testing we had our algorithm process a document for a professional. Without instructions, we had them login to our product and begin the correction process.
Without any training or help, all our professionals were able to get through an entire document. Further, they cited the process as “easy.”

The end results
Our initial goal was to eliminate the time required to process a document; however, the high expectations for data accuracy required a person to review it. During our final round of tests, we found users were able to perform a single review in ten minutes— a 65% reduction in time. Further, in that ten minutes they were helping teach our model so that one day we could realize our initial goal.